
hive> show functions;2)显示自带的函数的用法
hive> desc function upper;3)详细显示自带的函数的用法
hive> desc function extended upper;常用内置函数 NVL
nvl(v1,v2)
参数:第一个参数是字段,第二个参数是常量值或者某个字段;
功能是如果v1为NULL,则返回v2的值,否则返回value的值,如果两个参数都为NULL ,则返回NULL
select dept_id, sum(case when sex ='男' then 1 else 0 end) as '男', sum(case when sex ='女' then 1 else 0 end) as '女' from emp_sex group by dept_idCONCAt(string A/col, string B/col…)
参数:字符串或者字符串字段名
CONCAT_Ws(separator, str1, str2,…)- 第一个参数剩余参数间的分隔符
- 如果分隔符是 NULL,返回值也将为 NULL
- 后面的参数是字符串或者array
- 函数会跳过分隔符参数后的任何 NULL 和空字符串,分隔符将被加到被连接的字符串之间;
- 是一个聚合函数,将一列中的多行合并成一行
- 只接受基本数据类型
- 作用是将某字段的值进行去重汇总,返回值为array类型字段。
- collect_list(col) 函数和此函数的功能一致,只不过不会进行去重
需求
把星座和血型一样的人归类到一起。结果如下:
射手座,A 大海|凤姐 白羊座,A 孙悟空|猪八戒 白羊座,B 宋宋|苍老师
select
concat_ws(',',constellation,blood_type)
concat_ws('|',collect_set(name))
from
person_info
group by
constellation,blood_type
EXPLODE(col)
- udtf函数
- 参数类型:array类型或者map类型
- 功能:相当于flatmap,将一行拆分成多行
- LATERAL VIEW udtf(expression) tableAlias AS columnAlias
- 用于和split、 explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合
需求
将电影分类中的数组数据展开。结果如下:
《疑犯追踪》 悬疑 《疑犯追踪》 动作 《疑犯追踪》 科幻 《疑犯追踪》 剧情 《Lie to me》 悬疑 《Lie to me》 警匪 《Lie to me》 动作 《Lie to me》 心理 《Lie to me》 剧情 《战狼2》 战争 《战狼2》 动作 《战狼2》 灾难
SELECt movie, category_name FROM movie_info lateral VIEW explode(split(category,",")) movie_info_tmp AS category_name ;
说明:
将movie_info表侧写,将其movie_info表的category字段值用炸裂函数炸开,然后侧写形成临时表movie_info_tmp 并将炸裂的新行取名为category_name
说白了侧写的作用就是表字段炸裂后,形成多行,但是还和原来表关联
窗口函数 OVER()- 指定分析函数所作用的数据窗口大小,这个数据窗口大小可能会随着行的变而变化
- CURRENT ROW:当前行
- n PRECEDING:往前n行数据
- n FOLLOWING:往后n行数据
- UNBOUNDED PRECEDING 表示从前面的起点,
- UNBOUNDED FOLLOWING表示到后面的终点
- LAG(col,n,default_val):往前第n行数据
- LEAD(col,n, default_val):往后第n行数据
- NTILE(n):把有序窗口的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。
name,orderdate,cost
jack,2017-01-01,10 tony,2017-01-02,15 jack,2017-02-03,23 tony,2017-01-04,29 jack,2017-01-05,46 jack,2017-04-06,42 tony,2017-01-07,50 jack,2017-01-08,55 mart,2017-04-08,62 mart,2017-04-09,68 neil,2017-05-10,12 mart,2017-04-11,75 neil,2017-06-12,80 mart,2017-04-13,941. group by后over()窗口
(1) 查询在2017年4月份购买过的顾客及总人数
select name,count(*) over () from business where substring(orderdate,1,7) = '2017-04' group by name;
结论:select是在group by后面执行的,因此over()窗口大小是group by后的
2. over(partition by xxx)(2)查询顾客的购买明细及每个用户的
月购买总额
select *,sum(cost) over(partition by name,month(orderdate)) from business3.over(partition by xx order by xx)
(3) 将每个顾客的cost按照日期进行累加
select name,orderdate,cost, sum(cost) over() as sample1,--所有行相加 sum(cost) over(partition by name) as sample2,--按name分组,组内数据相加 sum(cost) over(partition by name order by orderdate) as sample3,--按name分组,组内数据累加 sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,--和sample3一样,由起点到当前行的聚合 sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --当前行和前面一行做聚合 sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,--当前行和前边一行及后面一行 sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --当前行及后面所有行 from business;
注意:
- rows必须跟在Order by 子句之后,对排序的结果进行限制,使用固定的行数来限制分区中的数据行数量
- 当order by 遇到相同的数据,那么窗口开到相同数据中的最后一条
id 1 2 3 3 4 5
select id, sum(id) over(order by id) from ...4. lag() over()
(4) 查看顾客上次的购买时间
select name, orderdate,cost, lag(orderdate,1,'1900-01-01') over(partition by name order by orderdate ) as time1, lag(orderdate,2) over (partition by name order by orderdate) as time2 from business;
lag(字段名,前面第n行,如果前面第n行没有该值的默认值)
5.ntile(n)(5) 查询前20%时间的订单信息
select * from (
select name,orderdate,cost, ntile(5) over(order by orderdate) sorted
from business
) t
where sorted = 1;
6.rank()
- RANK() 排序相同时会重复,总数不会变
- DENSE_RANK() 排序相同时会重复,总数会减少
- ROW_NUMBER() 会根据顺序计算
·
select name,
subject,
score,
rank() over(partition by subject order by score desc) rp,
dense_rank() over(partition by subject order by score desc) drp,
row_number() over(partition by subject order by score desc) rmp
from score;
name subject score rp drp rmp 孙悟空 数学 95 1 1 1 宋宋 数学 86 2 2 2 婷婷 数学 85 3 3 3 大海 数学 56 4 4 4 宋宋 英语 84 1 1 1 大海 英语 84 1 1 2 婷婷 英语 78 3 2 3 孙悟空 英语 68 4 3 4 大海 语文 94 1 1 1 孙悟空 语文 87 2 2 2 婷婷 语文 65 3 3 3 宋宋 语文 64 4 4 4分组函数
group sets()
这个函数用于多维分析,一个SQL可以按照多个维度groupby,并将结果union在一起
测试数据:
id name gender deptid 1001 zhangsan male 10 1002 lisi female 10 1003 banzhang female 20 1004 haiwang male 20 1005 banhua male 30 1006 shehuiyang female 30
sql语句:
select deptid,gender,count(*) from staff group by deptid,gender grouping sets((deptid,gender),deptid,gender,())
维度1:deptid,gender
维度2:deptid
维度3:gender
维度4:整体
NULL NULL就是按照整体统计的
10 NULL
20 NULL
30 NULL 按照deptid统计的
…
MR实现: 将维度作为map输出的key 也就是说map端来一条数据,输出多个key-value 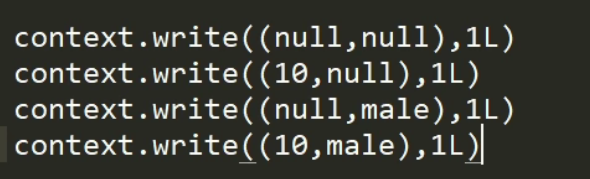
欢迎分享,转载请注明来源:内存溢出
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
评论列表(0条)