
概述#01、前言很多电影也上映,看电影前很多人都喜欢去**『豆瓣』**看影评,所以我爬取44130条**『豆瓣』**的
用户观影数据,分析**用户之间**的关系,**电影之间**的联系,以及**用户和电影之间**的
隐藏关系。# 02、爬取观影数据## 数据来源```pythonhttps://movIE.douban.com/```在****『豆瓣』****平台爬取用户观影数据。## 爬取用户列表### 网页分析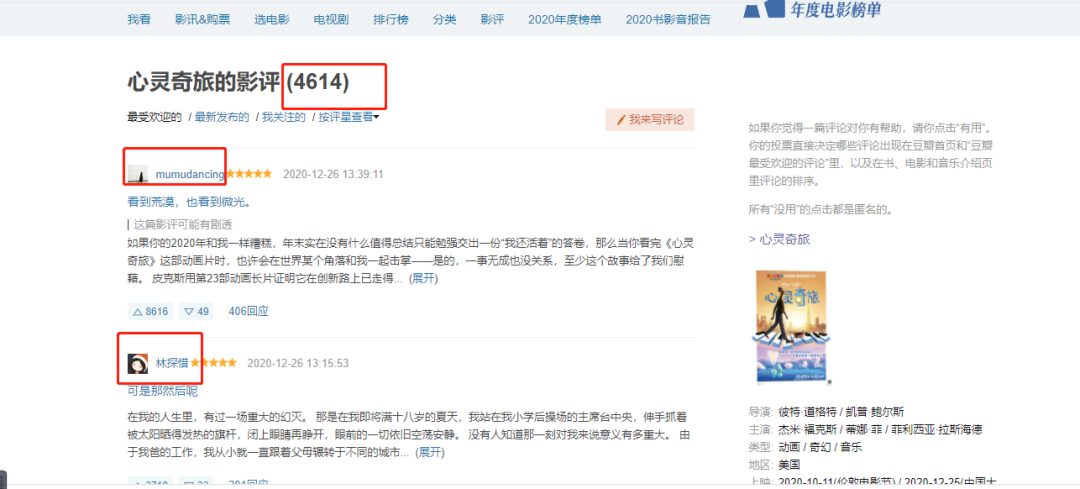为了获取用户,我选择了其中一部电影的影评,这样可以根据评论的用户去获取其用户名称(**后面爬取用户观影记录只需要****『用户名称』******)。```rubyhttps://movIE.douban.com/subject/24733428/revIEws?start=0```url中start参数是页数(page*20,每一页20条数据),因此start=0、20、40...,也就是**20的倍数**,通过改变start参数值就可以获取这**4614条用户的名称。**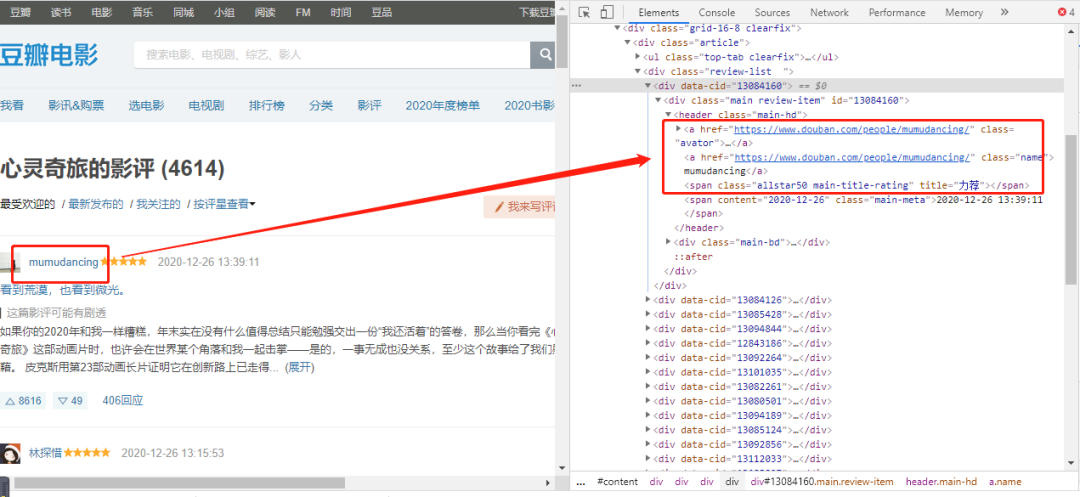查看网页的标签,可以找到******『用户名称』******值对应的标签属性。### 编程实现```pythoni=0url = "https://movIE.douban.com/subject/24733428/revIEws?start=" + str(i * 20)r = requests.get(url, headers=headers)r.enCoding = 'utf8's = (r.content)selector = etree.HTML(s) for item in selector.xpath('//*[@]/div'): userID = (item.xpath('.//*[@]/a[2]/@href'))[0].replace("https://www.douban.com/people/","").replace("/", "") username = (item.xpath('.//*[@]/a[2]/text()'))[0] print(userID) print(username) print("-----")```## 爬取用户的观影记录上一步爬取到****『用户名称』****,接着爬取用户观影记录需要用到****『用户名称』。****### 网页分析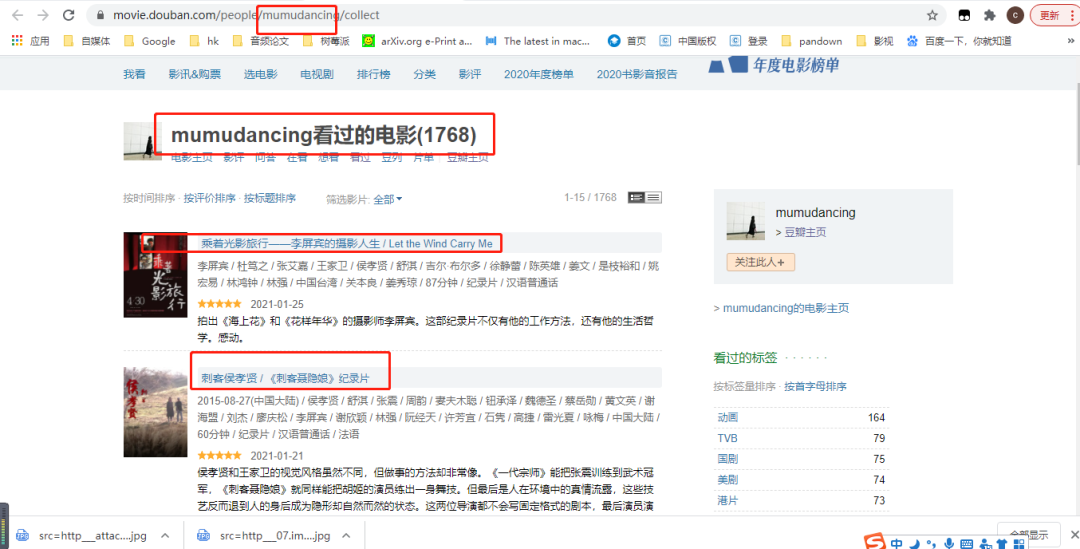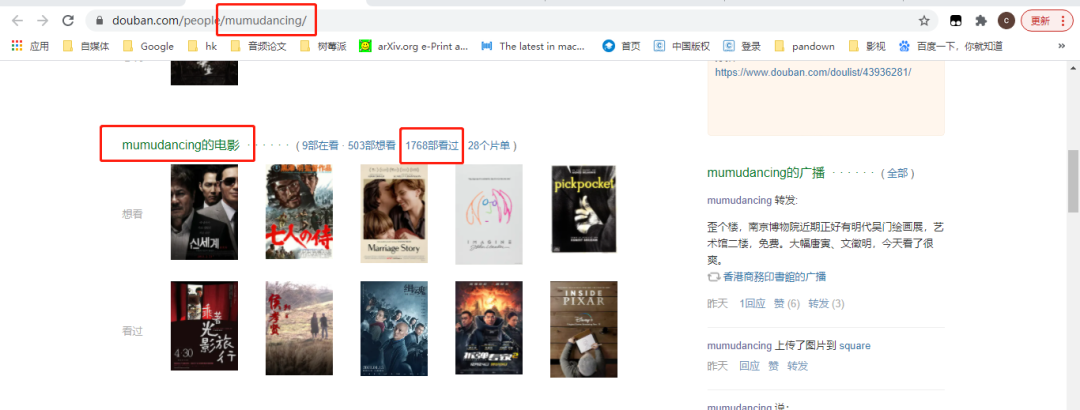```python#https://movIE.douban.com/people/{用户名称}/collect?start=15&sort=time&rating=all&filter=all&mode=grIDhttps://movIE.douban.com/people/mumudancing/collect?start=15&sort=time&rating=all&filter=all&mode=grID```通过改变****『用户名称』****,可以获取到不同用户的观影记录。url中start参数是页数(page*15,每一页15条数据),因此start=0、15、30...,也就是**15的倍数**,通过改变start参数值就可以获取这**1768条观影记录称。**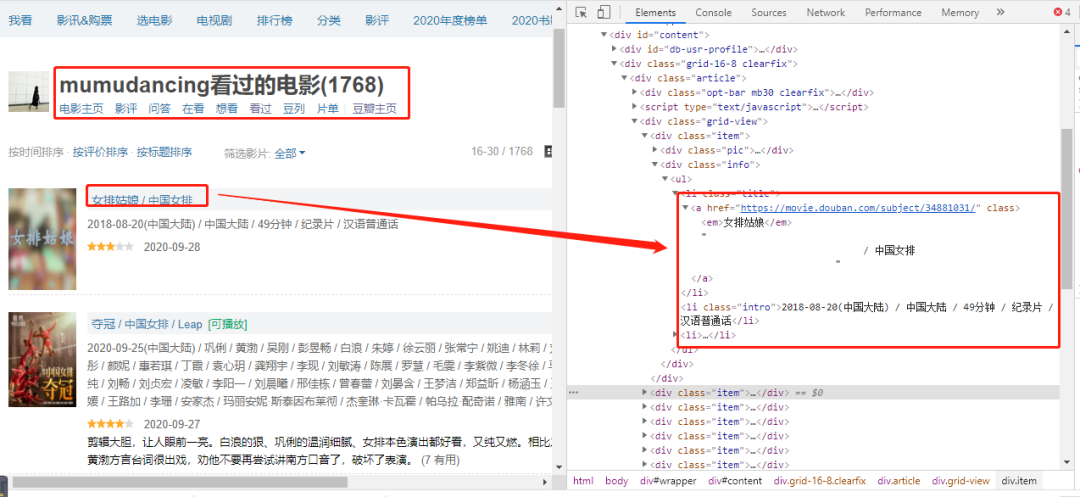查看网页的标签,可以找到****『电影名』****值对应的标签属性。### 编程实现```pythonurl = "https://movIE.douban.com/people/mumudancing/collect?start=15&sort=time&rating=all&filter=all&mode=grID"r = requests.get(url, headers=headers)r.enCoding = 'utf8's = (r.content)selector = etree.HTML(s)for item in selector.xpath('//*[@]/div[@]'): text1 = item.xpath('.//*[@]/a/em/text()') text2 = item.xpath('.//*[@]/a/text()') text1 = (text1[0]).replace(" ", "") text2 = (text2[1]).replace(" ", "").replace("\n", "") print(text1+text1) print("-----")```## 保存到excel### 定义表头```python# 初始化execl表def initexcel(filename): # 创建一个workbook 设置编码 workbook = xlwt.Workbook(enCoding='utf-8') # 创建一个worksheet worksheet = workbook.add_sheet('sheet1') workbook.save(str(filename)+'.xls') ##写入表头 value1 = [["用户", "影评"]] book_name_xls = str(filename)+'.xls' write_excel_xls_append(book_name_xls, value1)```excel表有两个标题(用户, 影评)### 写入excel```python# 写入execldef write_excel_xls_append(path, value): index = len(value) # 获取需要写入数据的行数 workbook = xlrd.open_workbook(path) # 打开工作簿 sheets = workbook.sheet_names() # 获取工作簿中的所有表格 worksheet = workbook.sheet_by_name(sheets[0]) # 获取工作簿中所有表格中的的第一个表格 rows_old = worksheet.nrows # 获取表格中已存在的数据的行数 new_workbook = copy(workbook) # 将xlrd对象拷贝转化为xlwt对象 new_worksheet = new_workbook.get_sheet(0) # 获取转化后工作簿中的第一个表格 for i in range(0, index): for j in range(0, len(value[i])): new_worksheet.write(i+rows_old, j, value[i][j]) # 追加写入数据,注意是从i+rows_old行开始写入 new_workbook.save(path) # 保存工作簿```定义了写入excel函数,这样爬起每一页数据时候调用写入函数将数据保存到excel中。最后采集了44130条数据(原本是4614个用户,每个用户大约有500~1000条数据,预计**400万条数据**)。但是为了演示分析过程,只爬取每一个用户的前30条观影记录(**因为前30条是最新的**)。最后这44130条数据会在**下面分享给大家**。# 03、数据分析
挖掘## 读取数据集```pythondef read_excel(): # 打开workbook data = xlrd.open_workbook('豆瓣.xls') # 获取sheet页 table = data.sheet_by_name('sheet1') # 已有内容的行数和列数 nrows = table.nrows dataList=[] for row in range(nrows): temp_List = table.row_values(row) if temp_List[0] != "用户" and temp_List[1] != "影评": data = [] data.append([str(temp_List[0]), str(temp_List[1])]) dataList.append(data) return dataList```从豆瓣.xls中读取全部数据放到dataList集合中。## 分析1:电影观看次数排行```python###分析1:电影观看次数排行def analysis1(): dict ={} ###从excel读取数据 movIE_data = read_excel() for i in range(0, len(movIE_data)): key = str(movIE_data[i][0][1]) try: dict[key] = dict[key] +1 except: dict[key]=1 ###从小到大排序 dict = sorted(dict.items(), key=lambda kv: (kv[1], kv[0])) name=[] num=[] for i in range(len(dict)-1,len(dict)-16,-1): print(dict[i]) name.append(((dict[i][0]).split("/"))[0]) num.append(dict[i][1]) plt.figure(figsize=(16, 9)) plt.Title('电影观看次数排行(高->低)') plt.bar(name, num, facecolor='lightskyblue', edgecolor='white') plt.savefig('电影观看次数排行.png')```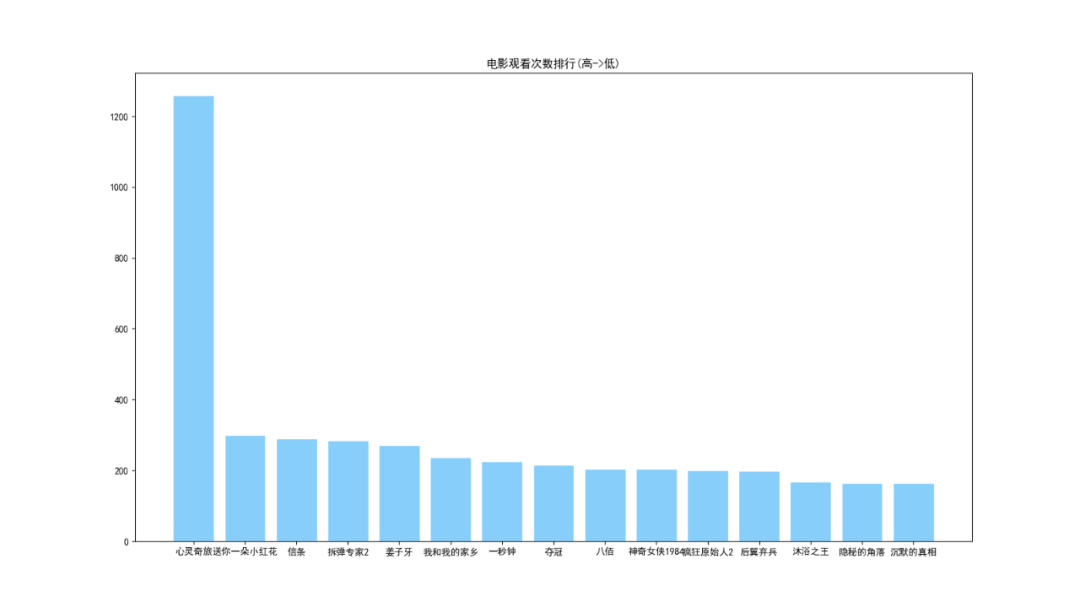### 分析1. 由于用户信息来源于 **『心灵奇旅』** 评论,因此其用户观看量最大。2. 最近的热播电影中,播放量排在第二的是 **『送你一朵小红花』**,信条和拆d专家2也紧跟其后。 ## 分析2:用户画像(用户观影相同率最高)```python###分析2:用户画像(用户观影相同率最高)def analysis2(): dict = {} ###从excel读取数据 movIE_data = read_excel() userList=[] for i in range(0, len(movIE_data)): user = str(movIE_data[i][0][0]) moive = (str(movIE_data[i][0][1]).split("/"))[0] #print(user) #print(moive) try: dict[user] = dict[user]+","+str(moive) except: dict[user] =str(moive) userList.append(user) num_dict={} # 待画像用户(取第一个) flag_user=userList[0] movIEs = (dict[flag_user]).split(",") for i in range(0,len(userList)): #判断是否是待画像用户 if flag_user != userList[i]: num_dict[userList[i]]=0 #待画像用户的所有电影 for j in range(0,len(movIEs)): #判断当前用户与待画像用户共同电影个数 if movIEs[j] in dict[userList[i]]: # 相同加1 num_dict[userList[i]] = num_dict[userList[i]]+1 ###从小到大排序 num_dict = sorted(num_dict.items(), key=lambda kv: (kv[1], kv[0])) #用户名称 username = [] #观看相同电影次数 num = [] for i in range(len(num_dict) - 1, len(num_dict) - 9, -1): username.append(num_dict[i][0]) num.append(num_dict[i][1]) plt.figure(figsize=(25, 9)) plt.Title('用户画像(用户观影相同率最高)') plt.scatter(username, num, color='r') plt.plot(username, num) plt.savefig('用户画像(用户观影相同率最高).png')```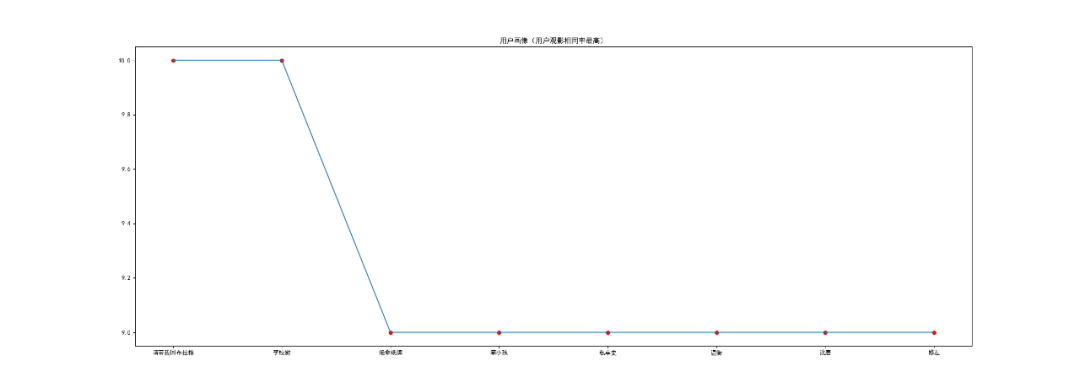### 分析以用户 **『mumudancing』** 为例进行用户画像1. 从图中可以看出,与用户 **『mumudancing』** 观影相同率最高的是:“请带我回布拉格”,其次是“李校尉”。 2. 用户:'绝命纸牌', '笨小孩', '私享史', '温衡', '沈唐', '修左',的**观影相同率****相同**。 ## 分析3:用户之间进行电影推荐```python###分析3:用户之间进行电影推荐(与其他用户同时被观看过)def analysis3(): dict = {} ###从excel读取数据 movIE_data = read_excel() userList=[] for i in range(0, len(movIE_data)): user = str(movIE_data[i][0][0]) moive = (str(movIE_data[i][0][1]).split("/"))[0] #print(user) #print(moive) try: dict[user] = dict[user]+","+str(moive) except: dict[user] =str(moive) userList.append(user) num_dict={} # 待画像用户(取第2个) flag_user=userList[0] print(flag_user) movIEs = (dict[flag_user]).split(",") for i in range(0,len(userList)): #判断是否是待画像用户 if flag_user != userList[i]: num_dict[userList[i]]=0 #待画像用户的所有电影 for j in range(0,len(movIEs)): #判断当前用户与待画像用户共同电影个数 if movIEs[j] in dict[userList[i]]: # 相同加1 num_dict[userList[i]] = num_dict[userList[i]]+1 ###从小到大排序 num_dict = sorted(num_dict.items(), key=lambda kv: (kv[1], kv[0])) # 去重(用户与观影率最高的用户两者之间重复的电影去掉) user_movIEs = dict[flag_user] new_movIEs = dict[num_dict[len(num_dict)-1][0]].split(",") for i in range(0,len(new_movIEs)): if new_movIEs[i] not in user_movIEs: print("给用户("+str(flag_user)+")推荐电影:"+str(new_movIEs[i]))```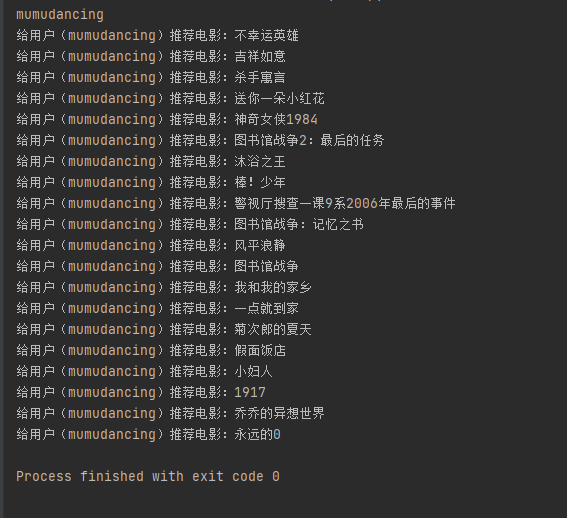### 分析以用户 **『mumudancing』** 为例,对用户之间进行**电影推荐**1. 根据与用户 **『mumudancing』** 观影率最高的用户(A)进行进行关联,然后获取用户(A)的全部观影记录 2. 将用户(A)的观影记录推荐给用户 **『mumudancing』**(去掉两者之间重复的电影)。 ## 分析4:电影之间进行电影推荐```python###分析4:电影之间进行电影推荐(与其他电影同时被观看过)def analysis4(): dict = {} ###从excel读取数据 movIE_data = read_excel() userList=[] for i in range(0, len(movIE_data)): user = str(movIE_data[i][0][0]) moive = (str(movIE_data[i][0][1]).split("/"))[0] try: dict[user] = dict[user]+","+str(moive) except: dict[user] =str(moive) userList.append(user) movIE_List=[] # 待获取推荐的电影 flag_movIE = "送你一朵小红花" for i in range(0,len(userList)): if flag_movIE in dict[userList[i]]: moives = dict[userList[i]].split(",") for j in range(0,len(moives)): if moives[j] != flag_movIE: movIE_List.append(moives[j]) data_dict = {} for key in movIE_List: data_dict[key] = data_dict.get(key, 0) + 1 ###从小到大排序 data_dict = sorted(data_dict.items(), key=lambda kv: (kv[1], kv[0])) for i in range(len(data_dict) - 1, len(data_dict) -16, -1): print("根据电影"+str(flag_movIE)+"]推荐:"+str(data_dict[i][0]))```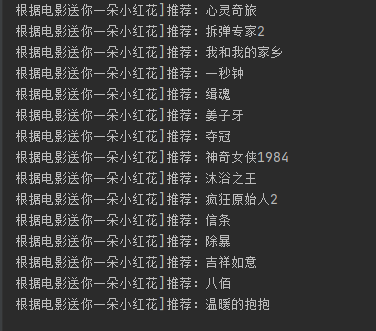### 分析以电影 **『送你一朵小红花』** 为例,对电影之间进行**电影推荐**1. 获取观看过 **『送你一朵小红花』** 的所有用户,接着获取这些用户各自的观影记录。 2. 将这些观影记录进行统计汇总(去掉“****送你一朵小红花****”),然后进行从高到低进行排序,最后可以获取到与电影 **『送你一朵小红花』** **关联度**最高排序的集合。 3. 将**关联度最高**的前15部电影给用户推荐。 # 04、总结1. 分析爬取豆瓣平台数据**思路**,并**编程实现**。 2. 对爬取的数据进行分析(**电影观看次数排行**、**用户画像**、**用户之间进行电影推荐**、**电影之间进行电影推荐**) 总结
以上是内存溢出为你收集整理的Python分析44130条用户观影数据,挖掘用户与电影之间的隐藏信息!全部内容,希望文章能够帮你解决Python分析44130条用户观影数据,挖掘用户与电影之间的隐藏信息!所遇到的程序开发问题。
如果觉得内存溢出网站内容还不错,欢迎将内存溢出网站推荐给程序员好友。
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
评论列表(0条)