
姓名
年龄
身高
体重
……
XX
12
170
150
XX1
23
165
120
多个这样形势的数据表,统称为数据库。对这些数据进行管理的软件称为数据库管理系统
数据库引入了索引
用户对数据库最频繁的 *** 作是进行数据查询 一般情况下 数据库在进行查询 *** 作时需要对整个表进行数据搜索 当表中的数据很多时 搜索数据就需要很长的时间 这就造成了服务器的资源浪费 为了提高检索数据的能力 数据库引入了索引机制
有关 索引 的比喻
从某种程度上 可以把数据库看作一本书 把索引看作书的目录 通过目录查找书中的信息 显然较没有目录的书方便 快捷
数据库索引实际是什么?(两部分组成)
索引是一个单独的 物理的数据库结构 它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单
索引在表中的角色
一个表的存储是由两部分组成的 一部分用来存放表的数据页面 另一部分存放索引页面 索引就存放在索引页面上
索引高效原理
通常 索引页面相对于数据页面来说小得多 当进行数据检索时 系统先搜索索引页面 从中找到所需数据的指针 再直接通过指针从数据页面中读取数据
索引的分类
在SQL Server 的数据库中按存储结构的不同将索引分为两类 簇索引(Clustered Index)和非簇索引(Nonclustered Index)
( )簇索引对表的物理数据页中的数据按列进行排序 然后再重新存储到磁盘上 即簇索引与数据是混为一体 的它的叶节点中存储的是实际的数据 由于簇索引对表中的数据一一进行了排序 因此用簇索引查找数据很快 但由于簇索引将表的所有数据完全重新排列了 它所需要的空间也就特别大 大概相当于表中数据所占空间的 % 表的数据行只能以一种排序方式存储在磁盘上 所以一个表只能有一个簇索引
( )非簇索引具有与表的数据完全分离的结构 使用非簇索引不用将物理数据页中的数据按列排序 非簇索引的叶节点中存储了组成非簇索引的关键字的值和行定位器 行定位器的结构和存储内容取决于数据的存储方式 如果数据是以簇索引方式存储的 则行定位器中存储的是簇索引的索引键如果数据不是以簇索引方式存储的 这种方式又称为堆存储方式(Heap Structure) 则行定位器存储的是指向数据行的指针 非簇索引将行定位器按关键字的值用一定的方式排序 这个顺序与表的行在数据页中的排序是不匹配的 由于非簇索引使用索引页存储因此它比簇索引需要更多的存储空间且检索效率较低但一个表只能建一个簇索引 当用户需要建立多个索引时就需要使用非簇索引了
小结 Clustered Index 是与物理数据混在一起并对物理数据进重排 就像使用拼音查字典Unclustered Index 是与物理数据完全分离的 利用额外空间对关键字进行重排 就像使用部首查字典
数据库索引应用
一 索引的概念
索引就是加快检索表中数据的方法 数据库的索引类似于书籍的索引 在书籍中 索引允许用户不必翻阅完整个书就能迅速地找到所需要的信息 在数据库中 索引也允许数据库程序迅速地找到表中的数据 而不必扫描整个数据库
二 索引的特点
索引可以加快数据库的检索速度
索引降低了数据库插入 修改 删除等维护任务的速度
索引创建在表上 不能创建在视图上
索引既可以直接创建 也可以间接创建
可以在优化隐藏中 使用索引
使用查询处理器执行SQL语句 在一个表上 一次只能使用一个索引
其他
三 索引的优点
创建唯一性索引 保证数据库表中每一行数据的唯一性
大大加快数据的检索速度 这也是创建索引的最主要的原因
加速表和表之间的连接 特别是在实现数据的参考完整性方面特别有意义
在使用分组和排序子句进行数据检索时 同样可以显著减少查询中分组和排序的时间
通过使用索引 可以在查询的过程中使用优化隐藏器 提高系统的性能
四 索引的缺点
创建索引和维护索引要耗费时间 这种时间随着数据量的增加而增加
索引需要占物理空间 除了数据表占数据空间之外 每一个索引还要占一定的物理空间 如果要建立聚簇索引 那么需要的空间就会更大
当对表中的数据进行增加 删除和修改的时候 索引也要动态的维护 降低了数据的维护速度
lishixinzhi/Article/program/MySQL/201311/29604究竟什么是数据库的事务,为什么数据库需要支持事务,为了实现数据库事务各种数据库的是如何设计的。还是只谈理解,欢迎大家来讨论。
1. 数据库事务是什么
事务的定义,已经有太多文章写过,我就不重复了。我理解的事务就是用来保证数据 *** 作符合业务逻辑要求而实现的一系列功能。换句话说,如果数据库不支持事务,上面业务系统的程序员就需要自己写代码保证相关数据处理逻辑的正确性。而数据库事务就是把一系列保证数据库处理逻辑正确性的通用功能在数据库内实现,并且尽量提高效率。
举个例子,数据库最开始普及就是在金融业,银行的存取款场景就是一个最典型的OLTP数据库场景,而事务就是设计用来保证类似场景的业务逻辑正确性的。
**原子性**,如果你要给家人转账,必须在你的账户里扣掉100块,在家人账户里加上100块,这两笔 *** 作需要一起完成,业务逻辑才是正确的。但是程序在做修改的时,肯定会有先后顺序,试想一下程序扣了你的钱,这个时候程序崩溃了,家人账户的钱没有加上。那这100块是不是消失了?你是不是要发疯?那么,就把这两笔 *** 作放进一个事务里,通过原子性保证,这两笔 *** 作要么都成功,要么都失败。这样才能保证业务逻辑的正确性。
**一致性**,有很多文章讲过一致性,但是很多人会把一致性跟原子性混在一起说。事务的一致性指的是指每一个事务必须保证执行之后所有库内的规则依旧成立。比如内外键,constraint,触发器等。举例来说,你在储蓄卡里有100元,理财账户里有100元,基金账户有100元,那么你在资产总和里会看到300元,这个300元必须是其他三个账户余额加在一起得到的。你在给家人转帐100元是从储蓄卡里转出去了100元,那么在数据库上可以通过创建触发器的方式,当储蓄卡余额账户减100元的同时,把资产总和也同步减去100,不然的话,就会出现逻辑上的错误,因为你已经转走了100块储蓄卡余额,实际资产总和应该是200,如果还是300,数据库状态就不一致了。所以实现事务的时候,必须要保证相关联的触发器以及其他所有的内部规则都执行成功,事务才能算执行成功。如果在减去资产总时出错,那么这笔转帐交易也不能成功。因为这样数据库就会进入不一致的状态。
那么这里跟原子性的区别到底在哪里呢?原子性是指个多个用户指令之间必须作为一个整体完成或失败,而一致性更多是数据库内的相关数据规则必须同时完成或失败。
**持久性**,最容易理解的一个,事务只要提交了,那么对数据库的修改就会保存下来不会丢了。简单来说,只要提交了,数据库就算崩溃了,重启之后你刚存的100块依然在你的账户里。
**隔离性**,每个事务相对于其他的事务是有一定独立性的,不能互相影响。因为数据库需要支持并发的 *** 作来提高效率。在并发 *** 作时,一定要通过 *** 作之间的隔离来保证业务逻辑的正确性。比如,你转帐100块给家人,一系列 *** 作的最后一步可能是输入验证码,这个时候转帐还没有完成,但是在数据库里你的账户对应的记录中已经减去100块,家人账户也加了100块,就等着验证码输入以后,事务提交,完成 *** 作。那么,这个时候,家人通过手机银行能够查到这100块么?你的答案可能是不能,因为这样才符合业务逻辑,因为你的转帐 *** 作还没有提交,事务还没有完成。那么数据库就应该保证这两个并发 *** 作之间具有一定的隔离性。
那么到底应该隔离到什么程度呢?隔离性又分为4个等级:由低到高依次为Read uncommitted(读未提交)、Read committed(读提交)、Repeatable read(可重复读取)、Serializable(序列化),这四个级别可以逐个解决脏读、不可重复读、幻象读这几类问题。这些东西是什么意思?请有兴趣的小伙伴自行百度,很多文章都写的很清楚。
那么怎么理解不同的隔离等级呢,首先要理解并发 *** 作,并发 *** 作就是指有不同的用户同时对一个数据进行读、写 *** 作,那么在这个过程中,每个用户应该看到什么数据才能保证业务逻辑的正确性呢? 如果是前面存取款的场景,我必须看到的是已经存进来的钱,也就是必须是已经提交的事务。而12306刷火车票呢,你可以看到有10张余票,但是在下单的时候告诉你票卖完了,因为同时有10个用户把票买掉了,你需要重新刷余票,这个也是可以接受的,也就是说我可以读到一些虚假的余票,这样在业务上也没有什么问题。那么在设计这两个不同系统时,就可以选择不同的事务隔离级别来实现不同的并发效果。不同的隔离等级就是要在系统的并发性和数据逻辑的严谨性之间做出的平衡。
2. 数据库如何实现事务
数据库实现事务会有多种不同的方式,但基本的原理类似,比如都需要对事务进行统一的编号处理,都需要记录事务的状态(是成功了还是失败了),都需要在数据存储的层面对事务进行支持,以明确哪些数据是被哪些事务、插入、修改和删除的。同时还会记录事务日志等,对事务进行系统化的管理以实现数据的原子性,一致性和持久性。
要实现事务的隔离性,最基础的就是通过加锁机制把并发 *** 作适当的串行化来保证数据 *** 作的正确逻辑。但是为了要保证系统具有良好的并发性能,必须要在实现事务隔离性时需要找到合理的平衡点。大部分数据库(包括Oracle,MySQL,Postgres在内)在做并发控制的时候都会采用MVCC(多版本并发控制)的机制来保证系统具有较高的并发性,不同数据库实现MVCC的具体方案也不尽相同,但其基本原理类似。
3. MVCC实现原理
所谓MVCC,就是数据库中的同一查询根据相关事务执行的先后顺序以及隔离级别的不同,可能会存在不同版本的结果,通过这样的手段来保证大部分查询 *** 作不会被修改 *** 作阻塞并保证数据逻辑的正确性。也就是数据库通过保存多个版本的数据( 历史 数据)来提高系统的并发查询能力。简单来说就是用存储空间来交换并发能力。下面以Postgres为例介绍一下MVCC的一种实现方式帮助大家理解这个重要的数据库概念。通过下面的图来解释Posrgres里最基本的数据可见性是如何实现多版本控制的。
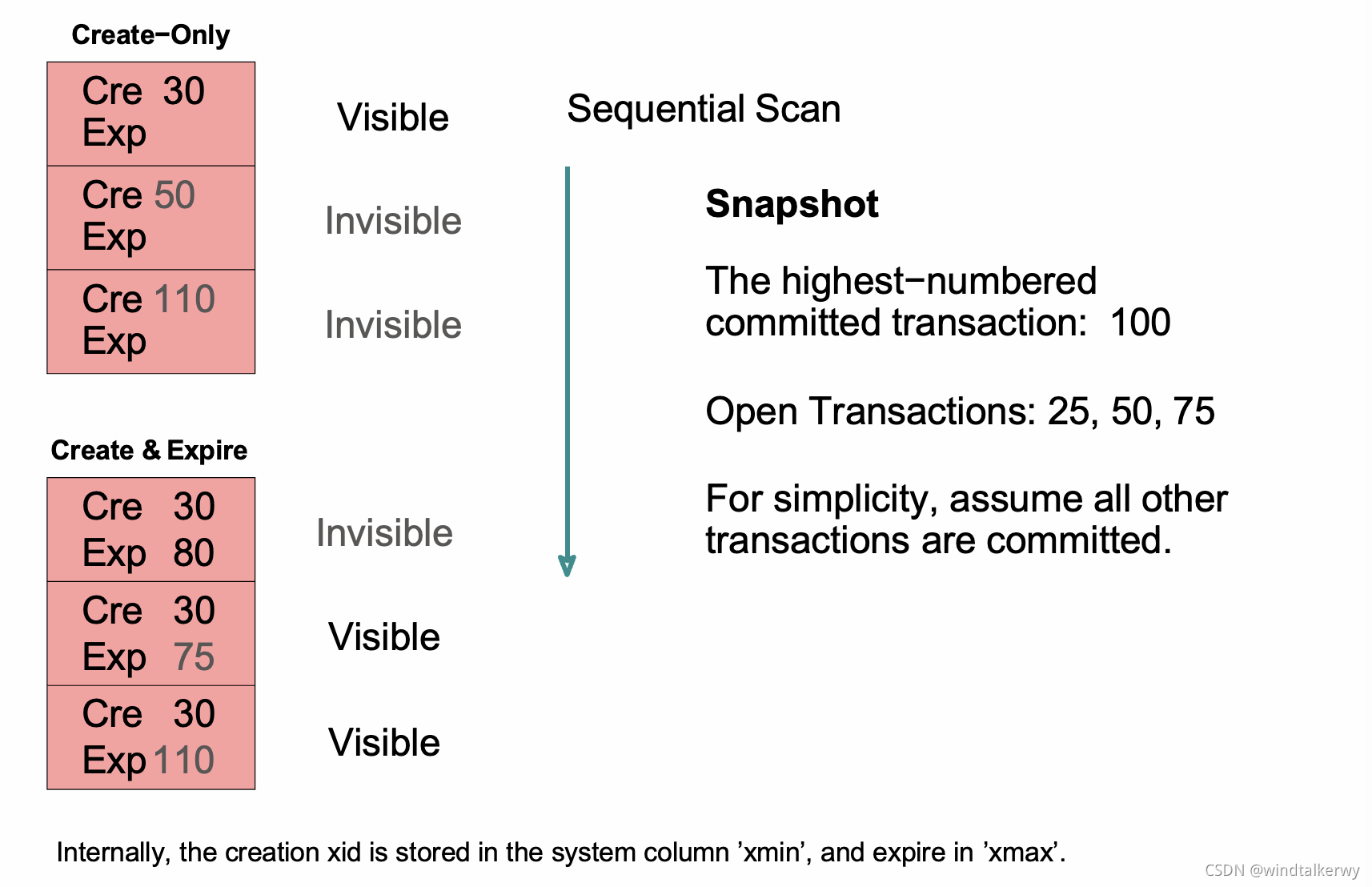
首先,Postgres里的每一个事务都有编号,这里可以简单理解为时间顺序编号,编号越大的事务发生越晚。然后,数据库里的每一行记录都会保存创建这条记录的事务号(Cre),也会在记录删除时保存删除这条记录的事务号(Exp),换句话说,只要Exp这里一列里记录了事务编号,就说明这条记录被删除了。那么一个事务应该能看见那些记录呢?Postgres里每一个事务都会保存一个当前系统的事务快照(Snapshot),这个快照里会保存事务创建时当前系统的最高(最晚)事务编号,以及目前还在进行中的事务编号。那么如上图所示的一个事务的快照里最高事务编号为100,目前正在进行的事务有25,50和75。那么对应左边数据记录,这6行数据的可见性就如同标注的一般:
第一行,Cre 30,没有删除,在100这个时间点,应该能看到。
第二行,Cre 50,没有删除,但是50这个事务还没有提交,正在进行中,所以看不见。
第三行,Cre 110,没有删除,但是100这个时间点110事务还没有发生,所以看不见。
第四行,Cre 30,Exp 80,在80的时候数据被删掉了,所以看不见。
第五行,Cre 30,Exp 75,在30的时候被创建,75时候被删掉了,但是75这个事务在100的时候还没有提交,所以这条记录在100的时候还没有删掉,所以看得见。
第六行,Cre30,Exp 110,在30的时被创建,110时候被删掉,但是在100时候,110还没有发生,所以看得见。
综上,就是这个事务对这六条记录的可见性,也就是一个数据版本。那么大家可以看一下如果另一个事务的快照里存的是最高事务编号为110,正在进行的事务为50,那么它能看到的数据应该是哪几行呢?同时大家也看到,Postgres里删除一行数据其实就是在这一行的Exp这个列记录一个删除事务的编号,相当于做了一个删除标记,而数据没有真正被删除,因此Postgres数据库需要定期做数据清理 *** 作(Vacuum)。Pstgres的在现实场景里会比这里介绍的要复杂,因为我们这里假定所有的事务最终都是正确提交了,如果存在某些事务没有提交的情况,那么可见性就会更加复杂,这里不再展开了。
数据库事务是基本的数据库概念,之前已经有很多很好文章做过介绍,这里希望能把自己的理解用比较通俗的描述分享给大家,欢迎来讨论交流。
欢迎分享,转载请注明来源:内存溢出
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
评论列表(0条)