
驱动学习:
kafka是业界消息中间件之楷模,他从网络设计、副本同步机制设计的很优秀,业界也很多公司都使用了kafka,当初我在BAT的内部后端serve有些场景也是通过Kafka解耦和实现一次性语义,我们公司目前kafka使用的场景也比较多例如tracking收集数据,前端能效组采集接口数据,埋点、大数据平台实时流计算,基本都使用kafka作为采集端,完成数据上报。
心得感受:
第一次看kafka broker的源码的时候,我是一个不懂scala语言的人,刚开始看这个代码很难受,过来这个难受时期,你会发现写kafka的作者水平相当厉害,写的如此优雅,网络模型简直业界楷模,包括他的注释都写的相当不错,所以学习kafka一定会有收获,今天把他分享的大家。

总结下,这里大概原理: accept组件监听9092端口,当一个客户端发起建立连接请求时,accept会完成一个新连接的建立,拿到对应的channel,然后将这个channel交给某个processor线程,由它来监听处理这个连接的read ,write事件,就是请求与响应。当这个客户端发送一个请求的时候,processor线程就能监听到,拿到对应的请求信息后,将请求信息塞到RequestChannel 组件里面的请求队列中。然后一堆RequestHandler 线程不停的从这个请求队列中获取请求信息,然后进行相应的业务逻辑处理,比如说发送消息的请求,它就会找到对应的parittion,写到对应partition在磁盘的文件中。处理完成业务逻辑后会有个处理结果需要告诉客户端,这个时候handler线程会将处理结果塞到对应processor的响应队列中。processor会不停的从自己对应的那个响应队列中获取响应,然后写回给对应的客户端。

首先我们全局的分析下borker启动到监听总个过程是个怎么样的呢?kafka broker 在启动的时候,会根据你配置的listeners 初始化它的网络组件,用来接收外界的请求,这个listeners你可能没配置过,它默认的配置是listeners=PLAINTEXT://:9092就是告诉kafka使用哪个协议,监听哪个端口,如果我们没有特殊的要求的话,使用它默认的配置就可以了,顶多是修改下端口这块。这个listeners是支持配置多套的,就是你可以监听多个端口,一个listener就对应着内部这么一套网络模型,我们就介绍一个listener的,多个其实都是一样的,就是对应着多套网络模型而已首先会创建一个accept 组件,这个组件对应着一个线程运行它,它主要是负责监听这个端口,打开一个selector,使用的是java原生的nio,打开一个serverSocketChannel,然后专门监听accept事件,建立网络连接的接着会为这个accept组件建立创建几个processor组件,每个processor都对应这个一个线程运行,默认是3个,是由num.network.threads这个参数配置的,这几个processor专门是接收请求,发送响应的,每个processor都会打开一个selector用于事件监听。当accept组件收到一个新连接请求的时候会建立一个新连接,就会拿到一个socketChannel,将这个连接交给processor,processor拿到这个channel之后就会注册到对应的selector上面,监听它的read事件,然后后续关于这个连接发送的请求就由某个processor线程来处理,处理完之后再将响应写回到这个连接对应的channel中。
1.2.2 接收端源码分析kafkaServerStartable.startup
启动代码入口main
socketServer = new SocketServer(config, metrics, kafkaMetricsTime)
socketServer.startup()
创建kafka socket
def startup() {
this.synchronized {
.........
endpoints.values.foreach { endpoint =>
for (i <- processorBeginIndex until processorEndIndex) {
processors(i) = new Processor(i,
time,
maxRequestSize,
requestChannel,
connectionQuotas,
connectionsMaxIdleMs,
protocol,
config.values,
metrics
)
}
val acceptor = new Acceptor(endpoint, sendBufferSize, recvBufferSize, brokerId,
processors.slice(processorBeginIndex, processorEndIndex), connectionQuotas)
acceptors.put(endpoint, acceptor)
Utils.newThread("kafka-socket-acceptor-%s-%d".format(protocol.toString, endpoint.port), acceptor, false).start()
acceptor.awaitStartup()
processorBeginIndex = processorEndIndex
}
}
这里就创建processors线程和acceptor线程
private[kafka] class Acceptor(val endPoint: EndPoint,
val sendBufferSize: Int,
val recvBufferSize: Int,
brokerId: Int,
processors: Array[Processor],
connectionQuotas: ConnectionQuotas) extends AbstractServerThread(connectionQuotas) with KafkaMetricsGroup {
private val nioSelector = NSelector.open()
val serverChannel = openServerSocket(endPoint.host, endPoint.port)
this.synchronized {
processors.foreach { processor =>
Utils.newThread("kafka-network-thread-%d-%s-%d".format(brokerId, endPoint.protocolType.toString, processor.id), processor, false).start()
}
}
// TODO: 这里是重写run methods
def run() {
serverChannel.register(nioSelector, SelectionKey.OP_ACCEPT)
startupComplete()
try {
var currentProcessor = 0
while (isRunning) {
try {
val ready = nioSelector.select(500)
if (ready > 0) {
val keys = nioSelector.selectedKeys()
val iter = keys.iterator()
while (iter.hasNext && isRunning) {
try {
val key = iter.next
iter.remove()
if (key.isAcceptable)
accept(key, processors(currentProcessor))
else
throw new IllegalStateException("Unrecognized key state for acceptor thread.")
// round robin to the next processor thread
currentProcessor = (currentProcessor + 1) % processors.length
} catch {
case e: Throwable => error("Error while accepting connection", e)
}
}
}
}
catch {
// We catch all the throwables to prevent the acceptor thread from exiting on exceptions due
// to a select operation on a specific channel or a bad request. We don't want the
// the broker to stop responding to requests from other clients in these scenarios.
case e: ControlThrowable => throw e
case e: Throwable => error("Error occurred", e)
}
}
} finally {
debug("Closing server socket and selector.")
swallowError(serverChannel.close())
swallowError(nioSelector.close())
shutdownComplete()
}
}
private def openServerSocket(host: String, port: Int): ServerSocketChannel = {
val socketAddress =
if(host == null || host.trim.isEmpty)
new InetSocketAddress(port)
else
new InetSocketAddress(host, port)
val serverChannel = ServerSocketChannel.open()
serverChannel.configureBlocking(false)
serverChannel.socket().setReceiveBufferSize(recvBufferSize)
try {
serverChannel.socket.bind(socketAddress)
info("Awaiting socket connections on %s:%d.".format(socketAddress.getHostName, serverChannel.socket.getLocalPort))
} catch {
case e: SocketException =>
throw new KafkaException("Socket server failed to bind to %s:%d: %s.".format(socketAddress.getHostName, port, e.getMessage), e)
}
serverChannel
}
def accept(key: SelectionKey, processor: Processor) {
val serverSocketChannel = key.channel().asInstanceOf[ServerSocketChannel]
val socketChannel = serverSocketChannel.accept()
try {
connectionQuotas.inc(socketChannel.socket().getInetAddress)
socketChannel.configureBlocking(false)
socketChannel.socket().setTcpNoDelay(true)
socketChannel.socket().setKeepAlive(true)
socketChannel.socket().setSendBufferSize(sendBufferSize)
debug("Accepted connection from %s on %s. sendBufferSize [actual|requested]: [%d|%d] recvBufferSize [actual|requested]: [%d|%d]"
.format(socketChannel.socket.getInetAddress, socketChannel.socket.getLocalSocketAddress,
socketChannel.socket.getSendBufferSize, sendBufferSize,
socketChannel.socket.getReceiveBufferSize, recvBufferSize))
processor.accept(socketChannel)
} catch {
case e: TooManyConnectionsException =>
info("Rejected connection from %s, address already has the configured maximum of %d connections.".format(e.ip, e.count))
close(socketChannel)
}
}
@Override
def wakeup = nioSelector.wakeup()
}
sacla跟其他语言不太一样,他可以到处创建函数,然后再函数内部调用外部函数, 首先我们看看这段代码干了一些什么事情,他主要创建acceptor线程,然后注册OP_READ事件,将接收的线程交给processor线程处理,写框架主要在于细节看看是否处理完美,我们首先来看看连接过多怎么办,那么肯定有一个阈值,可以设置,如果超过阈值抛出异常就可以jvm自动会帮你捕获到异常,交给业务系统。
def accept(socketChannel: SocketChannel) {
newConnections.add(socketChannel)
wakeup()
}
弄个一容器缓存起来连接通道,然后唤醒线程进度处理。
override def run() {
startupComplete()
while(isRunning) {
try {
// setup any new connections that have been queued up
configureNewConnections()
// register any new responses for writing
processNewResponses()
try {
selector.poll(300)
} catch {
case e @ (_: IllegalStateException | _: IOException) =>
error("Closing processor %s due to illegal state or IO exception".format(id))
swallow(closeAll())
shutdownComplete()
throw e
}
selector.completedReceives.asScala.foreach { receive =>
try {
val channel = selector.channel(receive.source)
val session = RequestChannel.Session(new KafkaPrincipal(KafkaPrincipal.USER_TYPE, channel.principal.getName),
channel.socketAddress)
val req = RequestChannel.Request(processor = id, connectionId = receive.source, session = session, buffer = receive.payload, startTimeMs = time.milliseconds, securityProtocol = protocol)
requestChannel.sendRequest(req)
} catch {
case e @ (_: InvalidRequestException | _: SchemaException) =>
// note that even though we got an exception, we can assume that receive.source is valid. Issues with constructing a valid receive object were handled earlier
error("Closing socket for " + receive.source + " because of error", e)
close(selector, receive.source)
}
selector.mute(receive.source)
}
selector.completedSends.asScala.foreach { send =>
val resp = inflightResponses.remove(send.destination).getOrElse {
throw new IllegalStateException(s"Send for ${send.destination} completed, but not in `inflightResponses`")
}
resp.request.updateRequestMetrics()
selector.unmute(send.destination)
}
selector.disconnected.asScala.foreach { connectionId =>
val remoteHost = ConnectionId.fromString(connectionId).getOrElse {
throw new IllegalStateException(s"connectionId has unexpected format: $connectionId")
}.remoteHost
// the channel has been closed by the selector but the quotas still need to be updated
connectionQuotas.dec(InetAddress.getByName(remoteHost))
}
} catch {
// We catch all the throwables here to prevent the processor thread from exiting. We do this because
// letting a processor exit might cause bigger impact on the broker. Usually the exceptions thrown would
// be either associated with a specific socket channel or a bad request. We just ignore the bad socket channel
// or request. This behavior might need to be reviewed if we see an exception that need the entire broker to stop.
case e : ControlThrowable => throw e
case e : Throwable =>
error("Processor got uncaught exception.", e)
}
}
这个方法就是真正要干事的工人, 他主要实现了发送线程与接收线程解耦
apis = new KafkaApis(socketServer.requestChannel, replicaManager, consumerCoordinator,
kafkaController, zkUtils, config.brokerId, config, metadataCache, metrics, authorizer)
requestHandlerPool = new KafkaRequestHandlerPool(config.brokerId, socketServer.requestChannel, apis, config.numIoThreads)
brokerState.newState(RunningAsBroker)
这里主要是RequestHadler默认参数# The number of threads doing disk I/O num.io.threads=8 配置这个参数接收与处理线程池的大小
def sendRequest(request: RequestChannel.Request) {
requestQueue.put(request)
}
这里就是等待消费线程进行消费,请看下面网络消费端的设计
1.3 网络响应端设计 1.3.1 总体架构分析
总结下: 这个图很清晰的说明我们客户发送一个请求,给服务端, KafkaRquestHadnler销毁requestQueue里面的数据,然后处理完后将结果放到responseQueue里面,Processor会遍历响应队列,然后返回给客户端
def run() {
while(true) {
try {
var req : RequestChannel.Request = null
while (req == null) {
// We use a single meter for aggregate idle percentage for the thread pool.
// Since meter is calculated as total_recorded_value / time_window and
// time_window is independent of the number of threads, each recorded idle
// time should be discounted by # threads.
val startSelectTime = SystemTime.nanoseconds
req = requestChannel.receiveRequest(300)
val idleTime = SystemTime.nanoseconds - startSelectTime
aggregateIdleMeter.mark(idleTime / totalHandlerThreads)
}
if(req eq RequestChannel.AllDone) {
debug("Kafka request handler %d on broker %d received shut down command".format(
id, brokerId))
return
}
req.requestDequeueTimeMs = SystemTime.milliseconds
trace("Kafka request handler %d on broker %d handling request %s".format(id, brokerId, req))
// TODO: 交给另外一个线程
apis.handle(req)
} catch {
case e: Throwable => error("Exception when handling request", e)
}
}
}
这里就是从队里里面拿取数据,然后交给api进行处理,
def receiveRequest(timeout: Long): RequestChannel.Request =
requestQueue.poll(timeout, TimeUnit.MILLISECONDS)
这里就是我们的数据就是我们在请求端进行放入,然后在这里将数据获取出来。
def handleProducerRequest(request: RequestChannel.Request) {
val produceRequest = request.requestObj.asInstanceOf[ProducerRequest]
val numBytesAppended = produceRequest.sizeInBytes
val (authorizedRequestInfo, unauthorizedRequestInfo) = produceRequest.data.partition {
case (topicAndPartition, _) => authorize(request.session, Write, new Resource(Topic, topicAndPartition.topic))
}
// the callback for sending a produce response
def sendResponseCallback(responseStatus: Map[TopicAndPartition, ProducerResponseStatus]) {
val mergedResponseStatus = responseStatus ++ unauthorizedRequestInfo.mapValues(_ => ProducerResponseStatus(ErrorMapping.TopicAuthorizationCode, -1))
var errorInResponse = false
mergedResponseStatus.foreach { case (topicAndPartition, status) =>
if (status.error != ErrorMapping.NoError) {
errorInResponse = true
debug("Produce request with correlation id %d from client %s on partition %s failed due to %s".format(
produceRequest.correlationId,
produceRequest.clientId,
topicAndPartition,
ErrorMapping.exceptionNameFor(status.error)))
}
}
def produceResponseCallback(delayTimeMs: Int) {
if (produceRequest.requiredAcks == 0) {
// no operation needed if producer request.required.acks = 0; however, if there is any error in handling
// the request, since no response is expected by the producer, the server will close socket server so that
// the producer client will know that some error has happened and will refresh its metadata
if (errorInResponse) {
val exceptionsSummary = mergedResponseStatus.map { case (topicAndPartition, status) =>
topicAndPartition -> ErrorMapping.exceptionNameFor(status.error)
}.mkString(", ")
info(
s"Closing connection due to error during produce request with correlation id ${produceRequest.correlationId} " +
s"from client id ${produceRequest.clientId} with ack=0n" +
s"Topic and partition to exceptions: $exceptionsSummary"
)
requestChannel.closeConnection(request.processor, request)
} else {
requestChannel.noOperation(request.processor, request)
}
} else {
val response = ProducerResponse(produceRequest.correlationId,
mergedResponseStatus,
produceRequest.versionId,
delayTimeMs)
requestChannel.sendResponse(new RequestChannel.Response(request,
new RequestOrResponseSend(request.connectionId,
response)))
}
}
// When this callback is triggered, the remote API call has completed
request.apiRemoteCompleteTimeMs = SystemTime.milliseconds
quotaManagers(RequestKeys.ProduceKey).recordAndMaybeThrottle(produceRequest.clientId,
numBytesAppended,
produceResponseCallback)
}
if (authorizedRequestInfo.isEmpty) {
sendResponseCallback(Map.empty)
} else {
val internalTopicsAllowed = produceRequest.clientId == AdminUtils.AdminClientId
// call the replica manager to append messages to the replicas
replicaManager.appendMessages(
produceRequest.ackTimeoutMs.toLong,
produceRequest.requiredAcks,
internalTopicsAllowed,
authorizedRequestInfo,
sendResponseCallback)
// if the request is put into the purgatory, it will have a held reference
// and hence cannot be garbage collected; hence we clear its data here in
// order to let GC re-claim its memory since it is already appended to log
produceRequest.emptyData()
}
}
这里通过写副本,副本写成功之后,完成回调。
二、Kafka 副本机制 2.1 总体架构分析
Kafka提供了数据复制算法保证,如果leader发生故障或挂掉,一个新leader被选举并被接受客户端的消息成功写入。Kafka确保从同步副本列表中选举一个副本为leader,或者说follower追赶leader数据。leader负责维护和跟踪ISR(In-Sync Replicas的缩写,表示副本同步队列。当producer发送一条消息到broker后,leader写入消息并复制到所有follower。消息提交之后才被成功复制到所有的同步副本。消息复制延迟受最慢的follower限制,重要的是快速检测慢副本,如果follower“落后”太多或者失效,leader将会把它从ISR中删除

1、Kafka 中分成两类副本:领导者副本(Leader Replica)和追随者副本(Follower Replica)。每个分区在创建时都要选举一个副本,称为领导者副本,其余的副本自动称为追随者副本。
2、Kafka 中,追随者副本是不对外提供服务的。追随者副本不处理客户端请求,它唯一的任务就是从领导者副本,所有的读写请求都必须发往领导者副本所在的 Broker,由该 Broker 负责处理。(因此目前kafka只能享受到副本机制带来的第 1 个好处,也就是提供数据冗余实现高可用性和高持久性)
3、领导者副本所在的 Broker 宕机时,Kafka 依托于 ZooKeeper 提供的监控功能能够实时感知到,并立即开启新一轮的领导者选举,从追随者副本中选一个作为新的领导者。老 Leader 副本重启回来后,只能作为追随者副本加入到集群中。
每个分区都有一个 ISR(in-sync Replica) 列表,用于维护所有同步的、可用的副本。首领副本必然是同步副本,而对于跟随者副本来说,它需要满足以下条件才能被认为是同步副本:
与 Zookeeper 之间有一个活跃的会话,即必须定时向 Zookeeper 发送心跳;
1、在规定的时间内从首领副本那里低延迟地获取过消息。
2、如果副本不满足上面条件的话,就会被从 ISR 列表中移除,直到满足条件才会被再次加入。
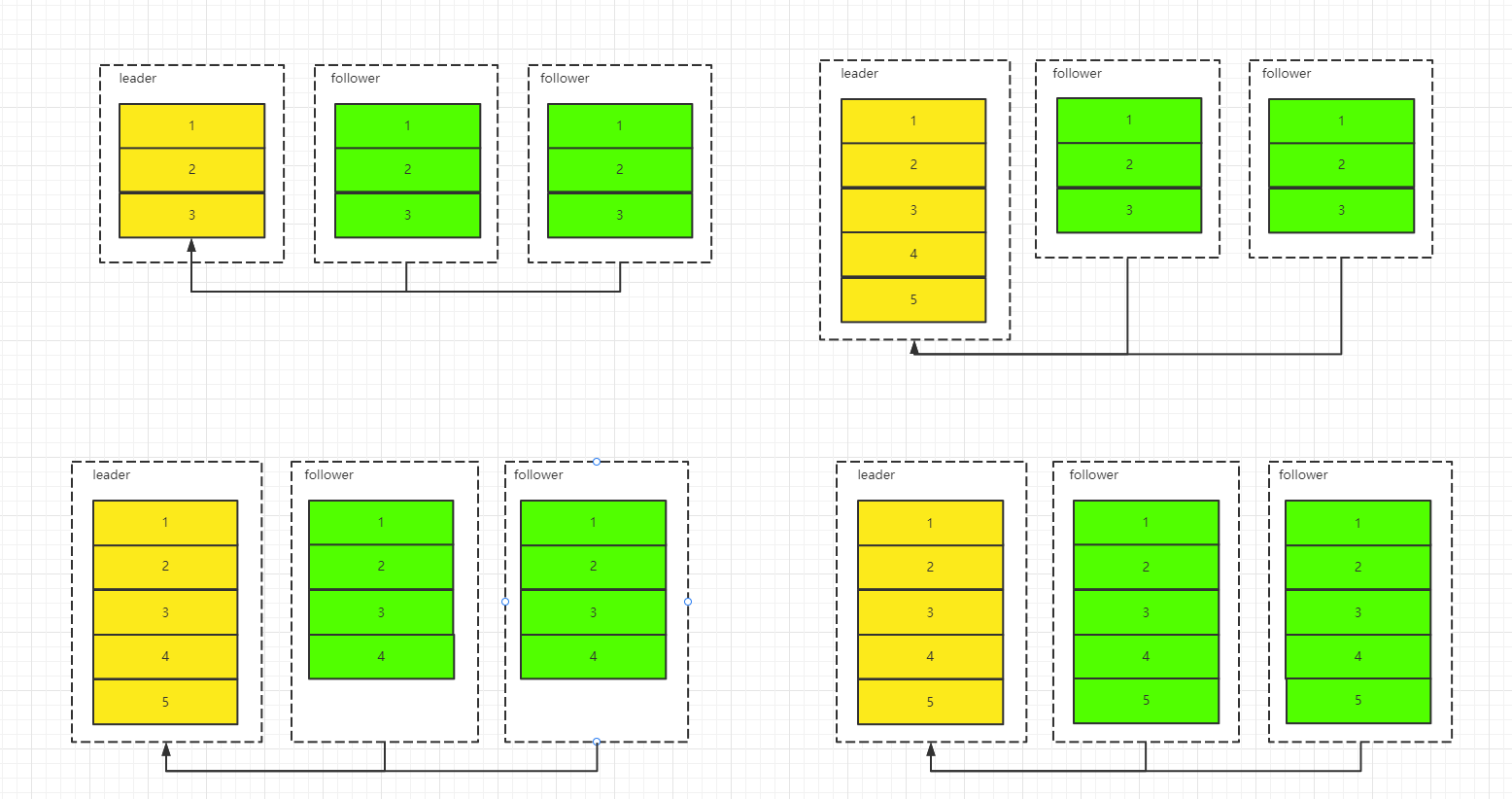
由此可见,Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的follower都复制完,这条消息才会被commit,这种复制方式极大的影响了吞吐率。而异步复制方式下,follower异步的从leader复制数据,数据只要被leader写入log就被认为已经commit,这种情况下如果follower都还没有复制完,落后于leader时,突然leader宕机,则会丢失数据。而Kafka的这种使用ISR的方式则很好的均衡了确保数据不丢失以及吞吐率。Kafka的ISR的管理最终都会反馈到Zookeeper节点上。具体位置为:/brokers/topics/[topic]/partitions/[partition]/state。目前有两个地方会对这个Zookeeper的节点进行维护:
- Controller来维护:Kafka集群中的其中一个Broker会被选举为Controller,主要负责Partition管理和副本状态管理,也会执行类似于重分配partition之类的管理任务。在符合某些特定条件下,Controller下的LeaderSelector会选举新的leader,ISR和新的leader_epoch及controller_epoch写入Zookeeper的相关节点中。同时发起LeaderAndIsrRequest通知所有的replicas。
- leader来维护:leader有单独的线程定期检测ISR中follower是否脱离ISR, 如果发现ISR变化,则会将新的ISR的信息返回到Zookeeper的相关节点中。
副本不同步的异常情况
- 慢副本:在一定周期时间内follower不能追赶上leader。最常见的原因之一是I / O瓶颈导致follower追加复制消息速度慢于从leader拉取速度。
- 卡住副本:在一定周期时间内follower停止从leader拉取请求。follower replica卡住了是由于GC暂停或follower失效或死亡。
- 新启动副本:当用户给主题增加副本因子时,新的follower不在同步副本列表中,直到他们完全赶上了leader日志。

3.2 稀疏索引
索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。 其中以索引文件中元数据3,497为例,依次在数据文件中表示第3个message(在全局partiton表示第368772个message)、以及该消息的物理偏移地址为497
message物理结构

参数说明

例如读取offset=368776的message,需要通过下面2个步骤查找。
第一步查找segment file ,其中00000000000000000000.index表示最开始的文件,起始偏移量(offset)为0.第二个文件00000000000000368769.index的消息量起始偏移量为368770 = 368769 + 1.同样,第三个文件00000000000000737337.index的起始偏移量为737338=737337 + 1,其他后续文件依次类推,以起始偏移量命名并排序这些文件,只要根据offset 二分查找文件列表,就可以快速定位到具体文件。 当offset=368776时定位到00000000000000368769.index|log
第二步通过segment file查找message 通过第一步定位到segment file,当offset=368776时,依次定位到00000000000000368769.index的元数据物理位置和00000000000000368769.log的物理偏移地址,然后再通过00000000000000368769.log顺序查找直到offset=368776为止。
从上述图3可知这样做的优点,segment index file采取稀疏索引存储方式,它减少索引文件大小,通过mmap可以直接内存 *** 作,稀疏索引为数据文件的每个对应message设置一个元数据指针,它比稠密索引节省了更多的存储空间,但查找起来需要消耗更多的时间。
页缓存技术 + 磁盘顺序写
你在写磁盘文件的时候,可以直接写入os cache 中,也就是仅仅写入内存中,接下来由 *** 作系统自己决定什么时候把os cache 里的数据真的刷入到磁盘中

顺序写磁盘
另外还有非常关键的一点,Kafka在写数据的时候是以磁盘顺序写的方式来落盘的,也就是说,仅仅将数据追加到文件的末尾(append),而不是在文件的随机位置来修改数据。对于普通的机械硬盘如果你要是随机写的话,确实性能极低,这里涉及到磁盘寻址的问题。但是如果只是追加文件末尾按照顺序的方式来写数据的话,那么这种磁盘顺序写的性能基本上可以跟写内存的性能本身是差不多的。
熟悉Linux *** 作系统原理的都知道,当我们把数据写入到文件系统之后,数据其实在 *** 作系统的page cache里面,并没有刷到磁盘上去。如果此时 *** 作系统挂了,其实数据就丢了。
两种实现方式
一方面,应用程序可以调用fsync这个系统调用来强制刷盘; 另一方面, *** 作系统有后 台线程,定期刷盘。
性能衡量
如果应用程序每写入1次数据,都调用一次fsync,那性能损耗就很大,所以一般都会 在性能和可靠性之间进行权衡。因为对应一个应用来说,虽然应用挂了,只要 *** 作系统 不挂,数据就不会丢。
另外, kafka是多副本的,当你配置了同步复制之后。多个副本的数据都在page cache里 面,出现多个副本同时挂掉的概率比1个副本挂掉,概率就小很多了。
参数设置
对于kafka来说,也提供了相关的配置参数,来让你在性能与可靠性之间权衡:
log.flush.interval.messages 在将消息刷新到磁盘之前,在日志分区上累积的消息数量
log.flush.interval.ms 在刷新到磁盘之前,任何topic中的消息保留在内存中的最长时间(以毫秒为单位)。如果未设置,则使用log.flush.scheduler.interval.ms中的值
log.flush.scheduler.interval.ms 日志刷新器检查是否需要将所有日志刷新到磁盘的频率
欢迎分享,转载请注明来源:内存溢出
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
评论列表(0条)